
LASDTab:基于局部注意力和語義聯(lián)合解碼器的中文工程表格結(jié)構(gòu)解析方法
中文題目:LASDTab:基于局部注意力和語義聯(lián)合解碼器的中文工程表格結(jié)構(gòu)解析方法
論文題目:LASDTab: A Complex Chinese Engineering Table Parsing Method Based on Local Attention and Semantic-Aware Unified Decoder
錄用期刊/會議:The 2025 Twentieth International Conference on Intelligent Computing (CCF C)
錄用/見刊時間:2025.4.28
作者列表:
1)李曉雪 中國石油大學(xué)(北京)人工智能學(xué)院 碩23
2)王智廣 中國石油大學(xué)(北京)人工智能學(xué)院 計算機系教師
3)劉志強 中國石油大學(xué)(北京)人工智能學(xué)院 碩23
4)劉若冰 中國石油大學(xué)(北京)人工智能學(xué)院 碩24
5)周 靜 中國石油大學(xué)(北京)人工智能學(xué)院 碩22
6)魯 強 中國石油大學(xué)(北京)人工智能學(xué)院 計算機系教師
文章簡介:
當(dāng)前方法應(yīng)用于中文工程表格時,仍然面臨兩大核心問題。其一,中文工程表格往往包含數(shù)百個單元格,導(dǎo)致結(jié)構(gòu)序列極為冗長,從而使模型在解析此類表格時難以取得理想效果。其二,表格解析通常涵蓋結(jié)構(gòu)預(yù)測、單元格位置預(yù)測與單元格內(nèi)容生成三個核心任務(wù),這些任務(wù)在空間與語義層面緊密耦合,但現(xiàn)有方法多將其獨立建模,忽略了多任務(wù)之間的相互依賴性。針對上述兩個問題,本文開展了一系列研究工作。
摘要:
中文工程表格往往包含數(shù)百個單元格,并且在解析時需要將復(fù)雜的表格結(jié)構(gòu)信息轉(zhuǎn)換為較長的序列表示,使得模型在解析此類表格時難以取得理想效果。此外,表格結(jié)構(gòu)預(yù)測、單元格位置預(yù)測和單元格內(nèi)容預(yù)測三個核心子任務(wù)在建模過程中通常相互獨立,當(dāng)前的研究未能充分考慮其在空間結(jié)構(gòu)與語義層面的緊密關(guān)聯(lián)。為應(yīng)對上述難題,本文提出了一種基于局部注意力和語義感知聯(lián)合解碼器的復(fù)雜中文工程表格解析框架——LASDTab。
設(shè)計與實現(xiàn):
首先,為了解決長表格問題,我們在結(jié)構(gòu)解碼器中引入了一種局部注意力機制,該機制僅關(guān)注輸入序列中與當(dāng)前位置鄰近的標(biāo)記,在降低計算復(fù)雜度的同時,能夠捕獲重要的局部結(jié)構(gòu)依賴。
傳統(tǒng)的Self-Attention機制的時空復(fù)雜度與文本的序列長度呈平方的關(guān)系,如圖1(a),這在很大程度上限制了模型的輸入不能太長。而局部注意力使用掩碼矩陣將注意力限制在一個窗口內(nèi),從而增強transformer對長序列的處理效率和準(zhǔn)確性,如圖1(b)。
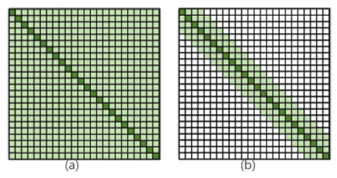
圖1 不同注意力機制的注意力范圍
其次,為了解決多任務(wù)建模分離問題,我們在語義感知聯(lián)合解碼器中,設(shè)計了一種語義信息驅(qū)動的聯(lián)合解碼機制。在聯(lián)合解碼過程中,內(nèi)容生成過程中的隱藏狀態(tài)被映射到一個共享的語義空間,并與位置預(yù)測特征進(jìn)行對齊,這種機制使位置預(yù)測模塊能夠直接從內(nèi)容生成的語義信息中獲益,從而顯著提升其對單元格邊界的預(yù)測準(zhǔn)確性。此外,我們通過結(jié)構(gòu)解碼器的動態(tài)觸發(fā)機制,在每次解碼到結(jié)構(gòu)標(biāo)簽<td></td>時,激活聯(lián)合解碼器解析當(dāng)前單元格的位置和內(nèi)容,保證任務(wù)之間的時序一致性。整體模型結(jié)構(gòu)圖如圖2所示。
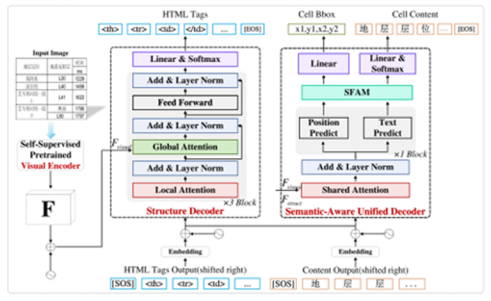
圖2 模型結(jié)構(gòu)圖
實驗結(jié)果及分析:
1、數(shù)據(jù)集
我們使用公共數(shù)據(jù)集 PubTabNet、FinTabNet,以及自建的 Long_PutTabNet 和 EGTabNet。Long_PutTabNet 是在 PubTabNet 的表結(jié)構(gòu)中選取的具有 300 個以上結(jié)構(gòu)標(biāo)記的表圖像,共有 82,027 個表。EGTabNet是一個由多層嵌套實體關(guān)系構(gòu)建的中文工程表數(shù)據(jù)集。
2、對比實驗結(jié)果及分析
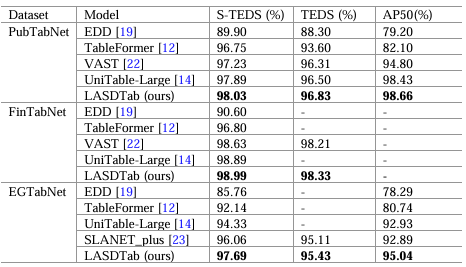
表1展示了各模型在三個數(shù)據(jù)集上的實驗結(jié)果。從實驗結(jié)果可以看出,本文方法在所有數(shù)據(jù)集上的 S-TEDS 、AP50和 TEDS 指標(biāo)均超過現(xiàn)有方法,充分驗證了其在復(fù)雜表格解析任務(wù)中的有效性。
表1 不同模型在表格解析任務(wù)中的 S-TEDS , TEDS和AP50 對比
結(jié)論:
我們提出了LASDTab,這是一個結(jié)合了局部注意力和語義感知聯(lián)合解碼器的新框架,用于增強表結(jié)構(gòu)預(yù)測、單元格位置預(yù)測和單元格內(nèi)容預(yù)測。局部注意機制提高了長且結(jié)構(gòu)緊密的表的結(jié)構(gòu)解碼精度,而SAUD通過共享注意力機制和語義對齊機制實現(xiàn)了單元位置和內(nèi)容的聯(lián)合建模,確保了任務(wù)之間的一致性。在三個數(shù)據(jù)集上的實驗結(jié)果表明,LASDTab在TEDS、S-TEDS和AP50指標(biāo)上顯著優(yōu)于六種主流表解析方法。這些結(jié)果驗證了該方法在高效準(zhǔn)確地解析復(fù)雜中文工程表中的有效性和魯棒性。未來的工作將進(jìn)一步探索該模型對于多語言表格數(shù)據(jù)和跨域表解析的可擴展性。
作者簡介:
王智廣,教授,博士生導(dǎo)師,北京市教學(xué)名師。中國計算機學(xué)會(CCF)高級會員,全國高校實驗室工作研究會信息技術(shù)專家指導(dǎo)委員會委員,全國高校計算機專業(yè)(本科)實驗教材與實驗室環(huán)境開發(fā)專家委員會委員,北京市計算機教育研究會常務(wù)理事。長期從事分布式并行計算、三維可視化、計算機視覺、知識圖譜方面的研究工作,主持或承擔(dān)國家重大科技專項子任務(wù)、國家重點研發(fā)計劃子課題、國家自然科學(xué)基金、北京市教委科研課題、北京市重點實驗室課題、地方政府委托課題以及企業(yè)委托課題20余項,在國內(nèi)外重要學(xué)術(shù)會議和期刊上合作發(fā)表學(xué)術(shù)論文70余篇,培養(yǎng)了100余名碩士博士研究生。